线程池,工具类
线程池
创建和销毁对象是很费时间的,所以有 创建统一的一个线程池。
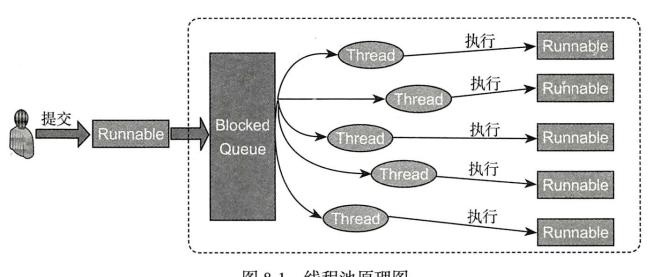
通俗理解就是有一个池子,里面存放着已经创建好的线程,当有任务提交给线程池执行时,池子中的某个线程会主动执行该任务。如果池子中的线程数量不够应付数量众多的任务时,则需要自动扩充新的线程到池子中,但是该数量时有限的,就好比池塘的水界线一样。当任务比较少的时候,池子中的线程能够自动回收,释放资源。为了能够异步地提交任务和缓存未被处理的任务,需要有一个任务队列。。
- newSingleThreadExecutor 创建一个单线程的线程池
- newFixedThreadPool 创建固定大小的线程池
- newCachedThreadPoll 创建一个可缓存的线程池
自定义线程池
线程池原理图
一个完整的线程池需要包括如下要素
- 任务队列 用于缓存提交的任务
- 线程数量管理功能 一个线程池必须能够很好地管理和控制线程数量,可通过如下三个参数来实现,比如创建线程池时初始的线程数量 init ;线程池自动扩充时最大的线程数量 max ;在线程池空闲时需要释放线程但是也要维护一定数量的活跃数量或者核心数量 core ;有了这三个参数就能够很好的控制线程池中的线程数量,将其维护在一个合理的范围之内,三者之间的关系是 init ≤ core ≤ max
- 任务拒绝策略 如果线程数量已达到上限且任务队列已满,则需要有相应的拒绝策略来通知任务提交者
- 线程工厂 主要用于个性化定制线程,比如将线程设置为守护线程以及设置线程名称等
- QueueSize 任务队列主要存放提交的 Runnable ,但是为了防止内存溢出,需要有 limit 数量对其进行控制
- Keepedalive 时间 该时间主要决定线程各个重要参数自动维护的时间间隔
- 步骤1 自定义拒绝策略接口
- 步骤2 自定义任务队列
- 步骤3 自定义线程池
- 步骤4 测试
ThreadPoolExecutor
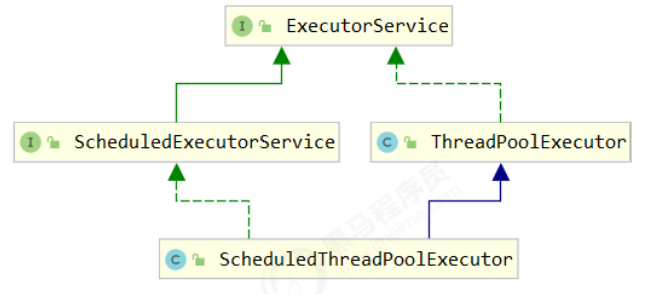
线程池状态
ThreadPoolExecutor 使用 int 的高 3 位来表示线程池状态,低 29 位表示线程数量
| 状态名 | 高 3 位 | 接收新任务 | 处理阻塞队列任务 | 说明 |
|---|---|---|---|---|
| RUNNABLE | 111 | Y | Y | |
| SHUTDOWN | 000 | N | Y | 不会接收新任务,但会处理阻塞队列剩余任务 |
| STOP | 001 | N | N | 会中断正在执行的任务,并抛弃阻塞队列任务 |
| TIDYING | 010 | —— | —— | 任务全执行完毕,活动线程为 0 即将进入终结 |
| TERMINATED | 011 | —— | —— | 终结状态 |
从数字上比较,TERMINATED > TIDYING > STOP > SHUTDOWN > RUNNING
这些信息存储在一个原子变量 ctl 中,目的是将线程状态域线程个数合二为一,这样就可以用一次 CAS 原子操作进行赋值
1
2
3
4
5
// c 为旧值, ctlOf 返回结果为新值
ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c))));
// rs 为高 3 位代表线程池状态, wc 为低 29 位代表线程个数,ctl 是合并它们
private static int ctlOf(int rs, int wc) { return rs | wc; }
构造方法
1
2
3
4
5
6
7
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
| 参数名 | 含义 |
|---|---|
| corePoolSize | 核心线程数目(最多保留的线程数) |
| maximumPoolSize | 最大线程数目 |
| keepAliveTime | 生存时间-针对救急线程 |
| unit | 时间单位-针对救急线程 |
| workQueue | 阻塞队列 |
| threadFactory | 线程工厂-可以为线程创建时起个好名字 |
| handler | 拒绝策略 |
工作方式
- 线程池中开始没有线程,当一个任务提交给线程池后,线程池会创建一个新线程来执行任务
- 当线程数达到 corePoolSize 并没有线程空闲,这时再加入任务,新加的任务会被加入 workQueue 队列排队,直到有空闲的线程
- 如果队列选择了有界队列,那么任务超过了队列大小时,会创建 maximumPoolSize - corePoolSize 数目的线程来救急
- 如果线程到达 maximumPoolSize 仍然有新任务这时会执行拒绝策略。拒绝策略 JDK 提供了四种实现,其它著名框架也提供了实现
- AbortPolicy 让调用者抛出 RejectedExecutionException 异常,这是默认策略
- CallerRunsPolicy 让调用者运行任务
- DiscardPolicy 放弃本次任务
- DiscardOldestPolicy 放弃队列中最早的任务,本任务取而代之
- Dubbo 的实现,在抛出 RejectedExecutionException 异常之前会记录日志,并 dump 线程栈信息,方便定位问题
- Netty 的实现,是创建一个新线程来执行任务
- ActiveMQ 的实现,带超时等待(60s)尝试放入队列,类似我们之前自定义的拒绝策略
- PinPoint 的实现,它使用了一个拒绝策略链,会逐一尝试策略链中每种拒绝策略
- 当高峰过去后,超过 corePoolSize 的救急线程如果一段时间没有任务做,需要结束节省资源,这个时间由 keepAliveTime 和 unit 来控制

根据这个构造方法,JDK Executors 类中提供了众多工厂方法来创建各种用途的线程池
newFixedThreadPool
1
2
3
4
5
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
特点:
- 核心线程数 == 最大线程数(没有救急线程被创建),因此也无需超时时间
- 阻塞队列是无界的,可以放任意数量的任务
评价 适用于任务量已知,相对耗时的任务
newCachedThreadPool
1
2
3
4
5
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
特点:
- 核心线程数 0,最大线程数是 Integer.MAX_VALUE ,救急线程的空闲生存时间是 60s,意味着
- 全部都是救急线程(60s 后可以回收)
- 救急线程可以无限创建
- 队列采用了 SynchronousQueue 实现特点是它没有容量,没有线程来取是放不进去的(一手交钱,一手交货)
评价 整个线程池表现为线程数会根据任务量不断增长,没有上线,当任务执行完毕,空闲 1 分钟后释放线程。适合任务数比较密集,但每个任务执行时间较短的情况
newSingleThreadExecutor
1
2
3
4
5
6
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
使用场景:
希望多个任务排队执行。线程数固定为 1 ,任务数多余 1 时,会放入无界队列排队。任务执行完毕,这唯一的线程也不会被释放。
区别:
- 自己创建一个单线程串行执行任务,如果任务执行失败而终止那么没有任何补救措施,而线程池还会新建一个线程,保证池的正常工作
- Executors.newSingleThreadExecutor() 线程个数始终为 1 ,不能修改
- FinalizableDelegatedExecutorService 应用的是装饰器模式,只对外暴露了 ExecutorService 接口,因此不能调用 ThreadPoolExecutor 中特有的方法
- Executors.newFixedThreadPool(1) 初始时为1,以后还可以修改
- 对外暴露的是 ThreadPoolExecutor 对象,可以强转后调用 setCorePoolSize 等方法进行修改
提交任务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 执行任务
void execute(Runnable command);
// 提交任务 task,用返回值 Future 获得任务执行结果
<T> Future<T> submit(Callable<T> task);
// 提交 tasks 中所有任务
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException;
// 提交 tasks 中所有任务,带超时时间
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException;
// 提交 tasks 中所有任务,哪个任务先成功执行完毕,返回此任务执行结果,其它任务取消
<T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException;
// 提交 tasks 中所有任务,哪个任务先成功执行完毕,返回此任务执行结果,其它任务取消,带超时时间
<T> T invokeAny(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
关闭线程池
shutdown
线程池状态变为 SHUTDOWN ,不会接收新任务,但已提交任务会执行完,此方法不会阻塞调用线程的执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
void shutdown(); public void shutdown() { final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { checkShutdownAccess(); // 修改线程池状态 advanceRunState(SHUTDOWN); // 仅会打断空闲线程 interruptIdleWorkers(); onShutdown(); // 扩展点 ScheduledThreadPoolExecutor } finally { mainLock.unlock(); } // 尝试终结(没有运行的线程可以立刻终结,如果还有运行的线程也不会等) tryTerminate(); }
shutdownNow
线程池状态变为 STOP ,不会接收新任务,会将队列中的任务返回,并用 interrupt 的方式中断正在执行的任务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
List<Runnable> shutdownNow() public List<Runnable> shutdownNow() { List<Runnable> tasks; final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { checkShutdownAccess(); // 修改线程池状态 advanceRunState(STOP); // 打断所有线程 interruptWorkers(); // 获取队列中剩余任务 tasks = drainQueue(); } finally { mainLock.unlock(); } // 尝试终结 tryTerminate(); return tasks; }
其它方法
1
2
3
4
5
6
7
// 不在 RUNNING 状态的线程池,此方法就返回 true
boolean isShutdown();
// 线程池状态是否是 TERMINATED
boolean isTerminated();
// 调用 shutdown 后,由于调用线程并不会等待所有任务运行结束
// 因此如果它想在线程池 TERMINATED 后做些事情,可以利用此方法等待
boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
Fork/Join 【略】
J.U.C Java.util.concurrent
AQS 原理
概述
全称是 AbstractQueuedSynchronizer ,是阻塞式锁和相关的同步器工具的框架。
AQS(AbstractQueuedSynchronizer)是 Java 并发包 java.util.concurrent 中的一个基础组件,用于构建锁和其他同步器。AQS 内部使用了一个整数(state)表示同步状态,以及一个先进先出的队列(CLH 队列)来存储那些获取锁失败的线程。以下是一个 ASCII 图来描述 AQS 的内部结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
+-----------------------------+
| AQS Structure |
+-----------------------------+
| State (int) | <- 表示锁的状态,例如 0 表示未锁定,1 表示已锁定
+-----------------------------+
| Head (Node) | <- 队列的头节点,表示当前正在等待的线程
+-----------------------------+
| Tail (Node) | <- 队列的尾节点,表示最近加入等待的线程
+-----------------------------+
| Queue (CLH Queue) | <- FIFO 队列,存储等待获取锁的线程
+-----------------------------+
| Node1 (Thread1) |
| Node2 (Thread2) |
| Node3 (Thread3) |
| ... |
| NodeN (ThreadN) |
+-----------------------------+
详细说明:
- State:
state是一个整数,表示锁的状态。例如,对于 ReentrantLock,state为 0 表示锁未被占用,state为 1 表示锁被占用。
- Head 和 Tail:
Head是队列的头节点,表示当前正在等待的线程。Tail是队列的尾节点,表示最近加入等待的线程。- 队列是双向链表结构,每个节点(Node)包含线程引用和状态信息。
- CLH 队列:
- CLH(Craig, Landin, and Hagersten)队列是一种无锁队列,用于存储那些尝试获取锁但失败的线程。
- 每个节点(Node)包含以下信息:
thread:等待的线程。waitStatus:节点的状态,可以是以下几种值:CANCELLED:线程被取消。SIGNAL:当前节点的线程需要被唤醒。CONDITION:线程在条件队列中等待。PROPAGATE:释放锁时需要传播信号。0:默认状态。
假设一个线程尝试获取锁但失败,它会被包装成一个 Node 并加入到队列中。队列的结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
+-----------------------------+
| AQS Structure |
+-----------------------------+
| State (int) = 1 |
+-----------------------------+
| Head (Node) |
+-----------------------------+
| Tail (Node) |
+-----------------------------+
| Queue (CLH Queue) |
+-----------------------------+
| Node1 (Thread1) | <- Head
| Node2 (Thread2) |
| Node3 (Thread3) |
| ... |
| NodeN (ThreadN) | <- Tail
+-----------------------------+
Node1是头节点,表示当前正在等待的线程。NodeN是尾节点,表示最近加入等待的线程。
当锁被释放时,AQS 会唤醒头节点的线程(Node1),尝试将锁传递给它。如果 Node1 获取锁成功,它会从队列中移除;如果失败,它会继续等待。
特点:
- 用 state 属性来表示资源的状态(分独占模式和共享模式),子类需要定义如何维护这个状态,控制如何获取锁和释放锁
- getState - 获取 state 状态
- setState - 设置 state 状态
- compareAndSetState - CAS 机制设置 state 状态
- 独占模式是只有一个线程能够访问资源,而共享模式可以允许多个线程访问资源
- 提供了基于 FIFO 的等待队列,类似于 Monitor 的 EntryList
- 条件变量来实现等待、唤醒机制,支持多个条件变量,类似于 Monitor 的 WaitSet
子类主要实现这样一些方法(默认抛出 UnsupportedOperationException )
- tryAcquire
- tryRelease
- tryAcquireShared
- tryReleaseShared
- isHeldExclusively
获取锁的姿势
1
2
3
4
// 如果获取锁失败
if (!tryAcquire(arg)) {
// 入队,可以选择阻塞当前线程 park unpark
}
释放锁的姿势
1
2
3
4
// 如果释放锁成功
if (tryRelease(arg)) {
// 让阻塞线程恢复运行
}
显式锁的分类
不可重入锁是指一种只允许一个线程在任意时刻获得该锁的锁实现。这意味着如果一个线程已经获得了该锁,在该线程释放锁之前,任何其他线程都无法获得该锁。
自定义同步器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
final class MySync extends AbstractQueuedSynchronizer {
@Override
protected boolean tryAcquire(int acquires) {
if (acquires == 1) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
}
return false;
}
@Override
protected boolean tryRelease(int acquires) {
if (acquires == 1) {
if (getState() == 0) {
throw new IllegalMonitorStateException();
}
setExclusiveOwnerThread(null);
setState(0);
return true;
}
return false;
}
protected Condition newCondition() {
return new ConditionObject();
}
@Override
protected boolean isHeldExclusively() {
return getState() == 1;
}
}
自定义同步器的作用是为了在多线程环境中提供更灵活的同步机制。Java中的同步器是用来管理线程的访问和通信的工具,可以通过自定义同步器来实现不同的同步策略和控制机制。
自定义同步器通常用于以下几种情况:
- 实现独占锁:可以通过自定义同步器来实现独占锁,控制只有一个线程可以获得锁,其他线程必须等待。
- 实现共享锁:可以通过自定义同步器来实现共享锁,允许多个线程同时获得锁,但限制同时获得锁的线程数量。
- 实现条件等待/通知机制:自定义同步器可以通过使用条件变量来实现线程的等待和通知机制,使得线程可以在特定条件下等待或被唤醒。
- 控制线程的执行顺序:通过自定义同步器,可以实现线程的有序执行,例如按照优先级或其他自定义规则来决定线程的执行顺序。
总之,自定义同步器允许开发人员根据特定需求设计和实现灵活的同步机制,以确保多线程环境下的线程安全和正确性。
自定义锁
有了自定义同步器,很容易复用 AQS ,实现一个功能完备的自定义锁
心得
起源
早期程序员会自己通过一种同步器去实现另一种相近的同步器,例如用可重入锁去实现信号量,或反之。这显然不够优雅,于是在 JSR166(Java 规范提案)中创建了 AQS ,提供了这种通用的同步器机制
目标
AQS 要实现的功能目标
- 阻塞版本获取锁 acquire 和非阻塞的版本尝试获取锁 tryAcquire
- 获取锁超时机制
- 通过打断取消机制
- 独占机制及共享机制
- 条件不满足时的等待机制
要实现的性能目标
Instead, the primary performance goal here is scalability: to predictably maintain efficiency even, or especially, when synchronizers are contended.
设计
AQS 的基本思想其实很简单
获取锁的逻辑
1 2 3 4 5 6
while(state 状态不允许获取) { if(队列中还没有此线程) { // 入队并阻塞 } } 当前线程出队
释放锁的逻辑
1 2 3
if(state 状态允许了) { 恢复阻塞的线程(s) }
要点
- 原子维护 state 状态
- 阻塞及恢复线程
- 维护队列
- state 设计
- state 使用 volatile 配合 CAS 保证其修改时的原子性
- state 使用了 32 bit int 来维护同步状态,因为当时使用 long 在很多平台下测试的结果并不理想
- 阻塞恢复设计
- 早起的控制线程暂停和恢复的 API 有 suspend 和 resume ,但它们时不可用的,因为如果先调用的 resume 那么 suspend 将感知不到
- 解决方法是使用 park & unpark 来实现线程的暂停和恢复,具体原理在之前讲过了,先 unpark 再 park 也没问题
- park & unpark 是针对线程的,而不是针对同步器,因此控制粒度更为精细
- park 线程还可以通过 interrupt 打断
- 队列设计
- 使用了 FIFO 先入先出队列,并不支持优先级队列
- 设计时借鉴了 CLH 队列,它是一种单向无锁队列
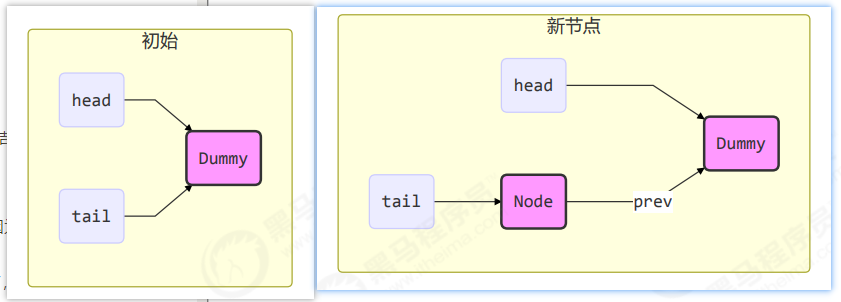
队列中有 head 和 tail 两个指针节点,都用 volatile 修饰配合 CAS 使用,每个节点有 state 维护节点状态入队伪代码,只需要考虑 tail 赋值的原子性
1
2
3
4
5
do {
// 原来的 tail
Node prev = tail;
// 用 CAS 在原来 tail 的基础上改为 node
} while(tail.compareAndSet(prev, node))
出队伪代码
1
2
3
4
5
// prev 是上一个节点
while((Node prev=node.prev).state != 唤醒状态) {
}
// 设置头节点
head = node;
CLH 好处:
- 无锁,使用自旋
- 快速,无阻塞
AQS 在一些方面改进了 CLH
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
private Node enq(final Node node) {
for (;;) {
Node t = tail;
// 队列中还没有元素 tail 为 null
if (t == null) {
// 将 head 从 null -> dummy
if (compareAndSetHead(new Node()))
tail = head;
} else {
// 将 node 的 prev 设置为原来的 tail
node.prev = t;
// 将 tail 从原来的 tail 设置为 node
if (compareAndSetTail(t, node)) {
// 原来 tail 的 next 设置为 node
t.next = node;
return t;
}
}
}
}
主要用到的 AQS 的并发工具类
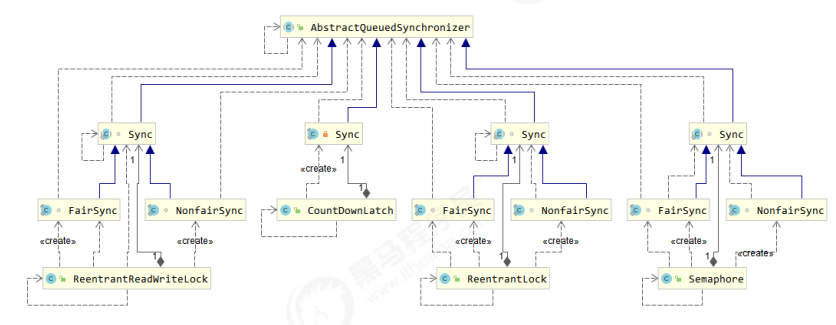
ReentrantLock 原理
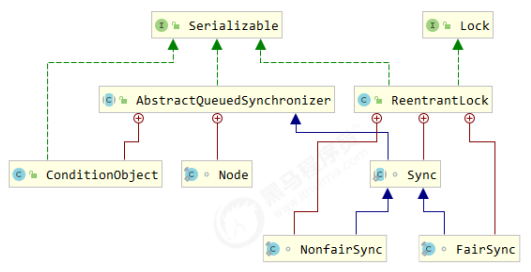
非公平锁实现原理
加锁解锁流程
先从构造器看,默认为非公平锁实现
1 2 3
public ReentrantLock() { sync = new NonfairSync(); }
NonfairSync 继承自 AQS
没有竞争时
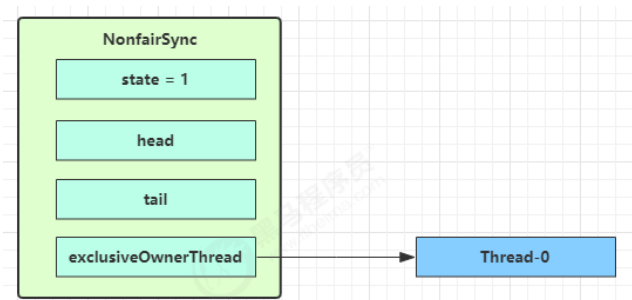
第一个竞争出现时
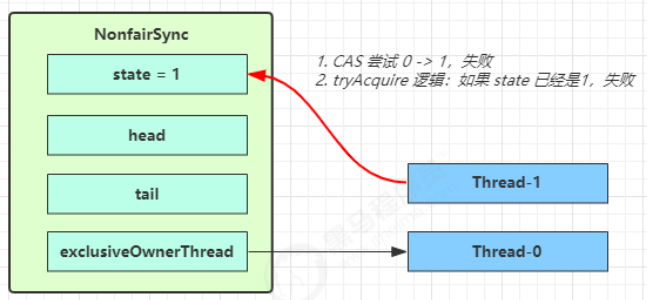
Thread-1 执行了
- CAS 尝试将 state 由 0 改为 1,结果失败
- 进入 tryAcquire 逻辑,这时 state 已经是1,结果仍然失败
- 接下来进入 addWaiter 逻辑,构造 Node 队列 图中黄色三角表示该 Node 的 waitStatus 状态,其中 0 为默认正常状态 Node 的创建是懒惰的 其中第一个 Node 称为 Dummy(哑元)或哨兵,用来占位,并不关联线程
当前线程进入 acquireQueued 逻辑
- acquireQueued 会在一个死循环中不断尝试获得锁,失败后进入 park 阻塞
- 如果自己是紧邻着 head(排第二位),那么再次 tryAcquire 尝试获取锁,当然这时 state 仍为 1,失败
- 进入 shouldParkAfterFailedAcquire 逻辑,将前驱 node,即 head 的 waitStatus 改为 -1,这次返回 false
- shouldParkAfterFailedAcquire 执行完毕回到 acquireQueued ,再次 tryAcquire 尝试获取锁,当然这时 state 仍为 1,失败
- 当再次进入 shouldParkAfterFailedAcquire 时,这时因为其前驱 node 的 waitStatus 已经是 -1,这次返回 true
- 进入 parkAndCheckInterrupt, Thread-1 park(灰色表示)
JUC的同步工具类
Semaphore
[ˈsɛməˌfɔr] 信号量,用来限制能同时访问共享资源的线程上限。
Semaphore 是 Java 并发包中的一个同步工具,用于控制同时访问某个资源的线程数量。它通过维护一个许可(permit)的数量来实现这一点。线程可以通过 acquire() 方法获取一个许可,通过 release() 方法释放一个许可。
以下是一个使用 Semaphore 的简单示例代码,模拟多个线程访问一个有限资源的场景:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
import java.util.concurrent.Semaphore;
public class SemaphoreExample {
public static void main(String[] args) {
// 创建一个Semaphore实例,初始许可数量为3
Semaphore semaphore = new Semaphore(3);
// 创建10个线程,模拟10个任务
for (int i = 0; i < 10; i++) {
int taskNumber = i + 1;
new Thread(() -> {
try {
// 获取一个许可
semaphore.acquire();
System.out.println("Task " + taskNumber + " is running.");
// 模拟任务执行时间
Thread.sleep((long) (Math.random() * 3000));
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 释放一个许可
semaphore.release();
System.out.println("Task " + taskNumber + " has finished.");
}
}).start();
}
}
}
- 代码说明
- 创建
Semaphore:Semaphore semaphore = new Semaphore(3);创建了一个Semaphore实例,初始许可数量为 3。这意味着最多允许 3 个线程同时访问资源。
- 获取许可:
semaphore.acquire();用于获取一个许可。如果当前没有可用的许可,线程会阻塞,直到有许可可用。
- 释放许可:
semaphore.release();用于释放一个许可。释放许可后,其他等待的线程可以获取许可并继续运行。
- 线程执行:
- 每个线程模拟一个任务,通过
Thread.sleep()模拟任务的执行时间。 - 在任务执行完成后,释放许可并打印任务完成的信息。
- 每个线程模拟一个任务,通过
CountdownLatch
用来进行线程同步协作,等待所有线程完成倒计时。
其中构造参数用来初始化等待计数值,await() 用来等待计数归零,countDown() 用来让计数减一。
CountDownLatch 是 Java 并发包中的一个同步工具,用于让一个或多个线程等待其他线程完成操作后再继续执行。它通过一个计数器来实现,当计数器的值减到零时,等待的线程会被唤醒并继续执行。
以下是一个使用 CountDownLatch 的示例代码,模拟多个线程完成任务后,主线程等待它们全部完成再继续执行的场景。
- 示例代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
import java.util.concurrent.CountDownLatch;
public class CountDownLatchExample {
public static void main(String[] args) {
// 创建一个CountDownLatch实例,初始计数为3
CountDownLatch latch = new CountDownLatch(3);
// 创建3个线程,模拟3个任务
for (int i = 0; i < 3; i++) {
int taskNumber = i + 1;
new Thread(() -> {
System.out.println("Task " + taskNumber + " is starting.");
try {
// 模拟任务执行时间
Thread.sleep((long) (Math.random() * 3000));
System.out.println("Task " + taskNumber + " has finished.");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 任务完成,计数器减1
latch.countDown();
}
}).start();
}
System.out.println("Main thread is waiting for all tasks to complete.");
try {
// 主线程等待计数器归零
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("All tasks are completed. Main thread continues.");
}
}
- 代码说明
- 创建
CountDownLatch:CountDownLatch latch = new CountDownLatch(3);创建了一个CountDownLatch实例,初始计数为 3。这意味着主线程会等待 3 个任务完成。
- 任务线程:
- 每个任务线程模拟一个任务,通过
Thread.sleep()模拟任务的执行时间。 - 任务完成时,调用
latch.countDown(),将计数器减 1。
- 每个任务线程模拟一个任务,通过
- 主线程等待:
- 主线程调用
latch.await(),等待计数器归零。如果计数器归零,主线程会继续执行。
- 主线程调用
CyclicBarrier
[ˈsaɪklɪk ˈbæriɚ] 循环栅栏,用来进行线程协作,等待线程满足某个计数。构造时设置『计数个数』,每个线程执行到某个需要“同步”的时刻调用 await() 方法进行等待,当等待的线程数满足『计数个数』时,继续执行
注意 CyclicBarrier 与 CountDownLatch 的主要区别在于 CyclicBarrier 是可以重用的 CyclicBarrier 可以被比喻为『人满发车』
以下是 Java 官方文档中提供的 CyclicBarrier 示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
class Solver {
final int N;
final float[][] data;
final CyclicBarrier barrier;
class Worker implements Runnable {
int myRow;
Worker(int row) { myRow = row; }
public void run() {
while (!done()) {
processRow(myRow);
try {
barrier.await();
} catch (InterruptedException ex) {
return;
} catch (BrokenBarrierException ex) {
return;
}
}
}
}
public Solver(float[][] matrix) {
data = matrix;
N = matrix.length;
Runnable barrierAction = () -> mergeRows(...);
barrier = new CyclicBarrier(N, barrierAction);
List<Thread> threads = new ArrayList<>(N);
for (int i = 0; i < N; i++) {
Thread thread = new Thread(new Worker(i));
threads.add(thread);
thread.start();
}
// wait until done
for (Thread thread : threads)
try {
thread.join();
} catch (InterruptedException ex) { }
}
}
- 示例说明
Solver类:- 用于解决一个并行计算问题,将矩阵的每一行分配给一个线程进行处理。
data是需要处理的矩阵,N是矩阵的行数。barrier是一个CyclicBarrier对象,用于同步所有线程。
Worker类:- 实现了
Runnable接口,每个线程处理矩阵的一行。 - 在每次处理完一行后,调用
barrier.await()等待其他线程。
- 实现了
CyclicBarrier的使用:- 在构造函数中,
CyclicBarrier被初始化为N,表示需要N个线程到达屏障点后才会继续执行。 barrierAction是一个可选的Runnable,在所有线程到达屏障点后执行,用于合并结果。
- 在构造函数中,
- 线程同步:
- 每个线程在完成自己的任务后调用
barrier.await(),等待其他线程完成。 - 当所有线程都到达屏障点后,
barrierAction被执行,然后所有线程继续执行后续任务。
- 每个线程在完成自己的任务后调用
线程安全集合类概述

线程安全集合类可以分为三大类:
- 遗留的线程安全集合如 Hashtable , Vector
- 使用 Collections 装饰的线程安全集合,如: Collections.synchronizedCollection Collections.synchronizedList Collections.synchronizedMap Collections.synchronizedSet Collections.synchronizedNavigableMap Collections.synchronizedNavigableSet Collections.synchronizedSortedMap Collections.synchronizedSortedSet
- java.util.concurrent.* 重点介绍 java.util.concurrent.* 下的线程安全集合类,可以发现它们有规律,里面包含三类关键词:Blocking、CopyOnWrite、Concurrent
- Blocking 大部分实现基于锁,并提供用来阻塞的方法
- CopyOnWrite 之类容器修改开销相对较重
- Concurrent 类型的容器
- 内部很多操作使用 cas 优化,一般可以提供较高吞吐量
- 弱一致性
- 遍历时弱一致性,例如,当利用迭代器遍历时,如果容器发生修改,迭代器仍然可以继续进行遍历,这时内容是旧的
- 求大小弱一致性,size 操作未必是 100% 准确
- 读取弱一致性
遍历时如果发生了修改,对于非安全容器来讲,使用 fail-fast 机制也就是让遍历立刻失败,抛出 ConcurrentModificationException,不再继续遍历
ConcurrentHashMap
- 死链问题
- JDK 8 ConcurrentHashMap
重要属性和内部类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// 默认为 0
// 当初始化时, 为 -1
// 当扩容时, 为 -(1 + 扩容线程数)
// 当初始化或扩容完成后,为 下一次的扩容的阈值大小
private transient volatile int sizeCtl;
// 整个 ConcurrentHashMap 就是一个 Node[]
static class Node<K,V> implements Map.Entry<K,V> {}
// hash 表
transient volatile Node<K,V>[] table;
// 扩容时的 新 hash 表
private transient volatile Node<K,V>[] nextTable;
// 扩容时如果某个 bin 迁移完毕, 用 ForwardingNode 作为旧 table bin 的头结点
static final class ForwardingNode<K,V> extends Node<K,V> {}
// 用在 compute 以及 computeIfAbsent 时, 用来占位, 计算完成后替换为普通 Node
static final class ReservationNode<K,V> extends Node<K,V> {}
// 作为 treebin 的头节点, 存储 root 和 first
static final class TreeBin<K,V> extends Node<K,V> {}
// 作为 treebin 的节点, 存储 parent, left, right
static final class TreeNode<K,V> extends Node<K,V> {}
重要方法
1
2
3
4
5
6
7
8
// 获取 Node[] 中第 i 个 Node
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i)
// cas 修改 Node[] 中第 i 个 Node 的值, c 为旧值, v 为新值
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v)
// 直接修改 Node[] 中第 i 个 Node 的值, v 为新值
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v)
构造器分析
可以看到实现了懒惰初始化,在构造方法中仅仅计算了 table 的大小,以后在第一次使用时才会真正创建
1
2
3
4
5
6
7
8
9
10
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
// tableSizeFor 仍然是保证计算的大小是 2^n, 即 16,32,64 ...
int cap = (size >= (long)MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
BlockingQueue
ConcurrentLinkQueue
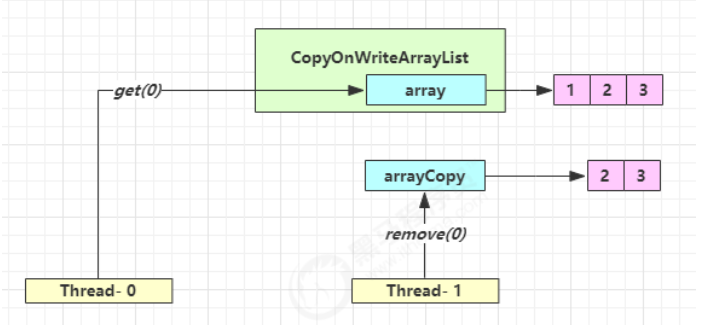
CopyOnWriteArrayList
CopyOnWriteArraySet 是它的马甲 底层实现采用了 写入时拷贝 的思想,增删改操作会将底层数组拷贝一份,更改操作在新数组上执行,这时不影响其它线程的并发读,读写分离。
get 弱一致性